

What happens when you type a URL into your browser?
Episode #15: High level overview of what happens after you type a URL in your browser.



Introduction
This is another episode in the series of articles about System design. If you missed any previous articles, read them in the System Design section.
This article will discuss what happens when you type a URL in your browser.
This is not the first article to discuss this topic; it won't be the last.
So, why should you bother reading it?
You are a Junior Software Engineer preparing for a System Design interview and need help figuring out where to start.
You are a more experienced developer who wants to go beyond the basics and can only find a few online resources to dive deeper.
I have already seen too many articles restating the basics and never providing anything more; or articles that never teach you anything useful that you can use in a real job; or covering topics by mixing up different levels of abstractions, going very deep in some areas but very shallow in others.
This is my attempt to solve these problems.
I started writing about this topic and soon realised I wanted to cover too much to fit into a single article.
That's why I decided to split it into two different articles at different levels of abstraction.
Here, we will cover only the details from a very high level. This article is best suited for beginners with no previous knowledge of how the web works.
In the following article, we will cover more details like HTTP headers, HTTPS key exchange, and much more at a lower level of abstraction.
If you are a Senior Software Engineer, you might still find this article helpful to have a simple high-level overview that you can use in a System Design interview as a prologue to deep dive later.
Motivation
In this section, I want to explain in more detail why splitting this article into two separate articles is the best strategy.
But first, a small disclaimer.
I love most of the content from ByteByteGo. I'm even a paid subscriber, but I think they missed the mark this time.
I want to provide my feedback on this article first, hoping how I address the topic is less confusing.

A couple of points:
The topic is discussed at different levels of abstraction. More about this later.
There are only four steps, but each has many other steps inside with no apparent order.
Who is the audience of this article? Too much information for a beginner, not enough for a more advanced user
A beginner will feel overwhelmed by the information packed in this infographic. If you are not familiar with these terms, mentioning them during an interview without being able to provide more information can lead to trouble.
To give an example. Do I have to mention DOM Tree and HTTPS Key exchange in a system design interview?
Not necessary. You can mention those topics if you can discuss them at length. Otherwise, there is so much to unpack that you can talk for hours about something else entirely.
What about a more senior developer, instead?
It is probable that they already know the information mentioned in the article and won't gain any new insights. Even after reading the article, they might need to conduct their own research, which could be challenging due to the overwhelming amount of articles, courses, and wiki pages available.
How do you solve this problem?
You just split the article into two separate articles.
One for beginners, with only the basics. One for more advanced developers, where instead, you go much deeper into the low-level details and provide lots of external resources.
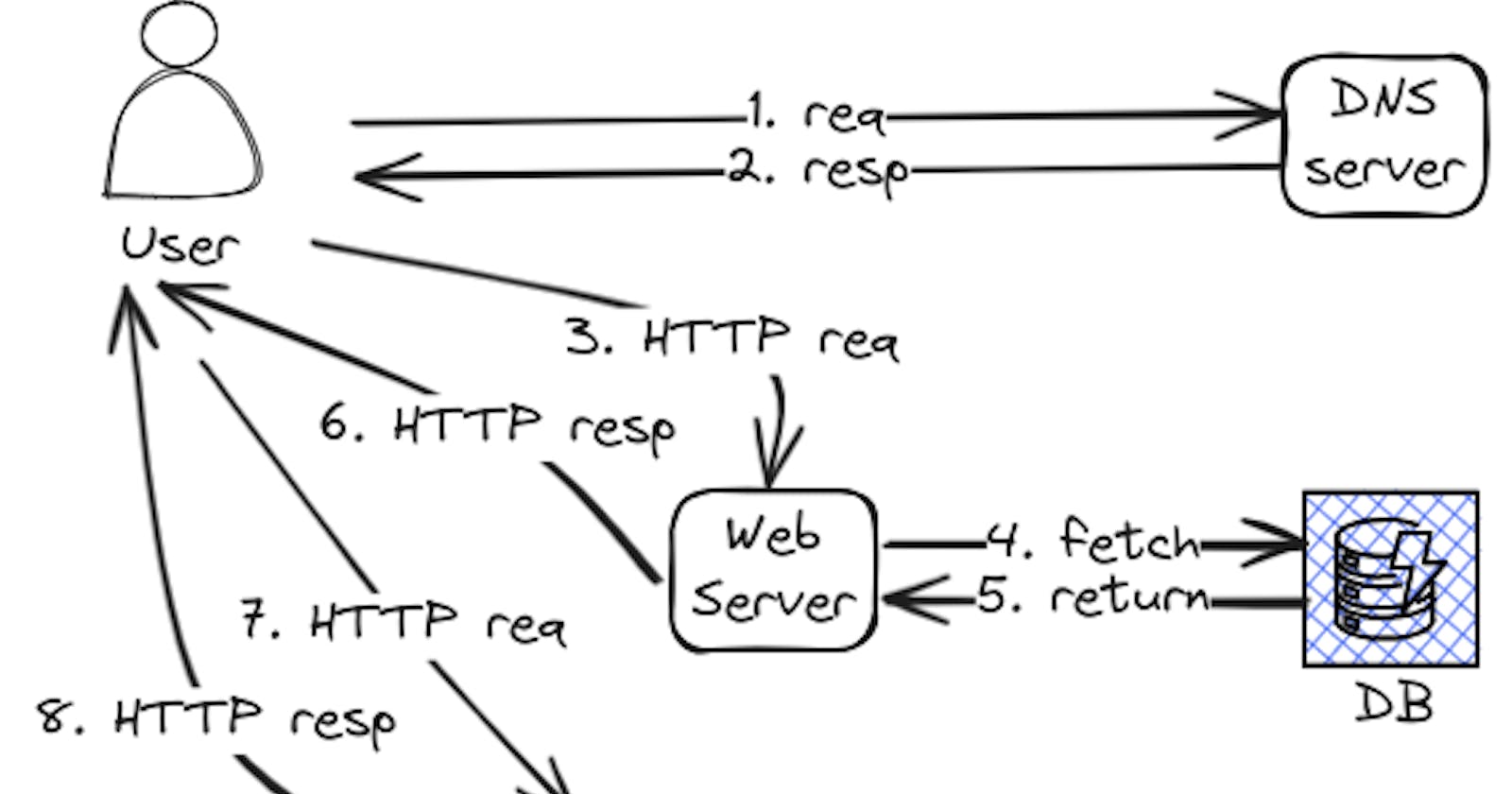
What happens at a high level?
You type a URL in your browser, wait for a second or less, the browser loads your HTML page, you enjoy your content, and move on to the next page.
This is what most internet users know about this topic, but what happens under the hood?
There are three main steps:
DNS resolution
HTTP request/response to either a web server or a CDN.
Web page rendering.
DNS resolution
Let's say that you found my article about CDNs at the URL:
https://cloudnativeengineer.substack.com/p/the-role-of-content-delivery-networks
The previous URL is made of three main parts:
A protocol:
httpsA domain name:
cloudnativeengineer.substack.com. This is a subdomain of the root domainsubstack.com, but the concept is the same at this level of abstraction.A path:
/p/the-role-of-content-delivery-networks
For a machine to resolve that URL, the domain name (or the subdomain here) has to be resolved into an IP address like 10.0.0.2.
Humans are not very good at remembering numbers. Also, the IP address associated with a domain name can change over time. It would be impossible for a human to keep track of them.
That's why a protocol called Domain Name System or DNS was invented.
In layman's terms, a DNS server is just a cache of key values, where the key is a human-readable domain name like substack.com and the value is an IP address like 10.0.0.2.
The browser asks a DNS server to resolve a domain name and returns the IP address of one or more web servers that can provide content for that web page.
HTTP request/response
Once the domain name has been correctly resolved, the browser sends an HTTP request to that IP address formatted as below:
GET /p/the-role-of-content-delivery-networks HTTP/1.1 Host: cloudnativeengineer.substack.com
HTTP is a text protocol in clear text (no encryption). You can craft an HTTP request with a text editor and inspect the content of those requests going through your local network.
Since that is not very secure, another protocol was invented called HTTPS that extends the HTTP protocol to prevent tampering and eavesdropping.
From the previous request, we can notice:
GETis the default HTTP verb to request a resource. There are more HTTP verbs that we will cover in the future.The HTTP verb is followed by the URL path and by the HTTP protocol version. In our case, the HTTP protocol
HTTP/1.1. This is the most common protocol version, but there are others.The HTTP requests contain the original domain name (resolved by the DNS) in an HTTP header called
Host. This header is mandatory since a single Web server might serve different websites. The web server won't know which web page to serve without this header.
What we discussed so far about HTTP protocol is the same, wheter you are talking to a web server or a CDN.
If you missed my article about the role of CDNs, head to Unravelling the Role of Content Delivery Networks in System Design to learn more about it.
A client usually sends the first request to a web server to request the main HTML page. That page might reference assets that a CDN serves. After the page is parsed, the browser might go back to the web server for more resources or as an alternative, and it might ask a CDN for static assets stored there.
A single HTML page can have just a few or tens or hundreds of resources to download. Some requests can happen in parallel, and some have to wait for others to finish.
Web page rendering
An HTML page is a text file in a markup format called HyperText Markup Language or HTML.
An HTML is made of three different components:
HTML for the content of the page.
CSS for the look and feel.
Javascript for any user interaction or "drawing" parts of the page.
Audio or images or other multi-media resources.
When the browser requests a URL, it first requests a main HTML page, and from that, it can discover other linked resources like Javascript files, CSS files, images, and so on.
The browser will try to request as many resources as possible in parallel but has a hard limit of 6 requests in parallel, at least in the version of the protocol HTTP 1.1, which we are discussing in this article.
This is a major cause of slow pages, so web developers have found all sorts of tricks to speed up the page loading time, like:
compression
enable caching and CDNs
Minify CSS and Javascript
More advanced HTTP protocols like HTTP 2.0 and 3.0 make some techniques redundant. More on this in the next article of this series.
All the resources in an HTML need to be processed in some way to render the final HTML page.
There is some back and forth between a browser and a Web server before a page can be rendered.
Resources
What happens when you type a URL into your browser?
Great video by Alex Xu, author of the newsletter ByteByteGo
It covers DNS resolution, the parts of a URL, TCP connection.
-
- This article goes into a lot more detail. Suitable for Senior Engineers who already know the basics and want to dive deep into some of the details.
This article was originally published at https://cloudnativeengineer.substack.com/p/what-happens-when-you-type-a-url